
Expand your horizons of OMICs data analysis and visualization





A roadmap to successful disease research and target identification strategies requires considerable resources spent on search, collection and interpretation of data during several months of work.
PandaOmics provides a unique opportunity to both explore the unknown of OMICs data and interpret it in the context of all the scientific data generated by the scientific community.
Sophisticated artificial intelligence algorithms suggest viable hypotheses of novel drug targets, reducing required time from several months to the span of just a few clicks
PandaOmics provides a unique opportunity to both explore the unknown of OMICs data and interpret it in the context of all the scientific data generated by the scientific community.
Sophisticated artificial intelligence algorithms suggest viable hypotheses of novel drug targets, reducing required time from several months to the span of just a few clicks
Zero bioinformatics experience is required
Core Features
Focus on data interpretation with a harmonized dataset OMICs Data Analysis
OMICs Data Analysis
Rank, score, and evaluate gene targets based on a disease of interest with AI-driven hypothesis generation
Target Identification & Evaluation
Use a proprietary pathway analysis approach to infer pathway activation and inhibition
Pathway Analysis
PandaOmics for Research
Access the full set of OMICs data generated
by the scientific community so far. You do not need
to spend your time trying to convert your data into
an interpretable format or wait for a bioinformatician
to do that for you — instead, you will find all
the data already processed and uploaded in a uniform way, so you can focus on science and data interpretation.
by the scientific community so far. You do not need
to spend your time trying to convert your data into
an interpretable format or wait for a bioinformatician
to do that for you — instead, you will find all
the data already processed and uploaded in a uniform way, so you can focus on science and data interpretation.
OMICs data analysis

Pathway analysis is a crucial step toward a complete understanding of how data works. It converts a list of seemingly unrelated genes into a connected story based on dysregulated molecular processes. PandaOmics uses a proprietary pathway analysis approach called iPanda to infer pathway activation or inhibition. Results published in Nature communications in 2016 demonstrated the algorithm outperforming other pathway analysis tools.
Comprehensive pathway analysis
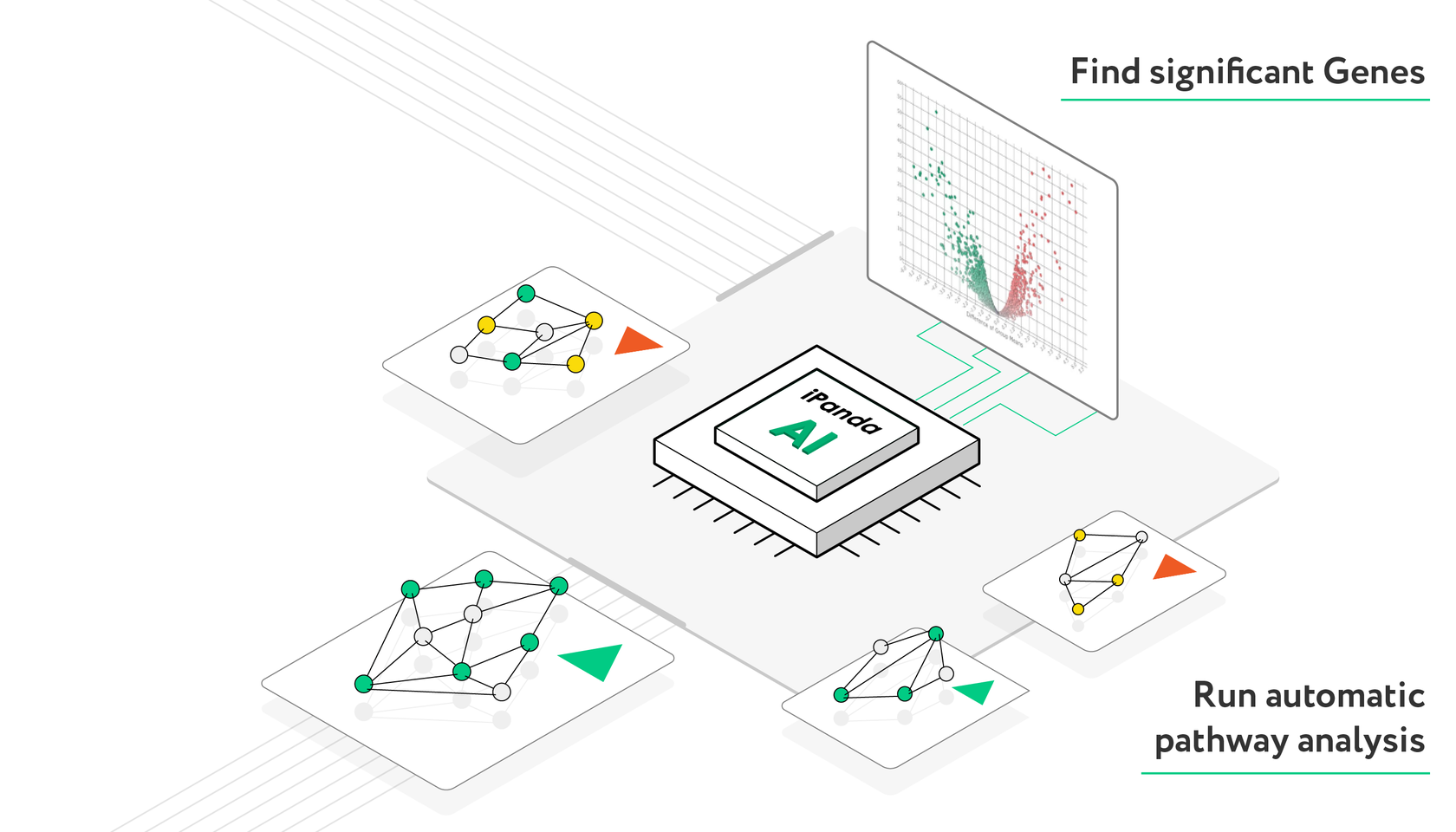
Once you have brought the context of related OMICs to your disease, start exploring the set of actionable drug target hypotheses that PandaOmics provides. A set of artificial intelligence algorithms analyzes the whole pool of text data, mentioning all significant genes from your experiment
in the context of the disease you are studying, and brings
both clear and hidden connections from the dataset
and publications, grants, patents, clinical trials, etc.
in the context of the disease you are studying, and brings
both clear and hidden connections from the dataset
and publications, grants, patents, clinical trials, etc.
Actionable
Target Identification
Target Identification

 5M
5M
OMICs data samplesA full spectrum of transcriptomics, genomics, epigenomics, proteomics, single cell data
generated by the scientific community 1.3M
1.3M
Compound & BiologicsDrugs from Phase 1 of clinical trial
till Launched phase 3M
3M
GrantsLife sciences research grant funding 3.8M
3.8M
PatentsPatents covering the life sciences industry 342K
342K
Clinical TrialsExplore extra knowledge related
to the clinical trials design 30M
30M
PublicationsPublished biomedical research results
PandaOmics for Target ID
PandaOmics allows target exploration even if you don't have any OMICs data. Starting from a disease of interest, the system applies an artificial intelligence hypothesis generation system to rank all related genes, taking into account all OMICs datasets stored in the system as well any connections from publications, grants, patents, clinical trials, etc.
Target Identification

Once you have a short list of putative targets, PandaOmics will help you to evaluate all the background evidence connecting them to the disease of interest.
Discover both molecular and text evidence connecting
a target to a disease
Discover both molecular and text evidence connecting
a target to a disease
Target Evaluation

Artificial intelligence algorithms predict the chances
of a potential target to enter Phase 1 of clinical trials
for any disease in the next five years, and estimate
the chance of a successful phase-to-phase transition
for disease-specific trials
of a potential target to enter Phase 1 of clinical trials
for any disease in the next five years, and estimate
the chance of a successful phase-to-phase transition
for disease-specific trials
Clinical Trials
transition prediction
transition prediction

Estimate the growth of attention to the gene given during the last five-year period (both disease-agnostic and disease-specific) the artificial intelligence technology predicts the burst of scientific community attention to a gene in the next three years
Target attention prediction

Explore an uncharted chemical space for perfect-fit compounds. Operate beyond all existing screening libraries and skip the effort of a perfect scaffold search and optimization.
Chemistry42 is a fully automated artificial intelligence platform that does everything for you in a week
Chemistry42 is a fully automated artificial intelligence platform that does everything for you in a week
Generate Novel compounds



Testimonials
We have had discussions with several AI startups and Insilico Medicine is the only company which provides excellent service not only with collaboration but also with software license. PandaOmics enabled us to analyze Microarray or RNAseq data easily and quickly. We are satisfied with its usability and the results generated from Insilico's software. We think PandaOmics is a worthwhile software for target identification. We also greatly appreciate their kind support. They are professionals, and always answer our questions quickly, precisely and kindly.

As we work to accelerate our understanding of diabetes and other diseases, PandaOmics is just the resource we sought to help us quickly access, analyze, visualize and interpret externally available data effectively to drive our research efforts. This new platform empowers our scientists to expedite biomarker identification, repurpose existing therapeutics and discover new drugs.

Dr. Daniel Robertson
Vice President of Digital Technology at the Indiana Biosciences Research Institute
Vice President of Digital Technology at the Indiana Biosciences Research Institute
COLLABORATIONS
This website uses cookies to ensure you get the best experience
OK